Cooperative Gazing Behaviors in Human Robot Interaction
When humans are addressing multiple robots with informative speech acts (Clark & Carlson 1982), their cognitive resources are shared between all the participating robot agents. For each moment, the user’s behavior is not only determined by the actions of the robot that they are directly gazing at, but also shaped by the behaviors from all the other robots in the shared environment. We define cooperative behavior as the action performed by the robots that are not capturing the user’s direct attention. In this series of studies, we are interested in how the human participants adjust and coordinate their own behavioral cues when the robot agents are performing different cooperative gaze behaviors.
We designed and implement a novel gaze-contingent platform to test out different types of cooperative gazing behaviors. The participants in the studies wore head-mounted eye-trackers. Their momentary eye gaze and first-person view video were recorded and processed in real time (see Figure below). The object color blobs were formed using a mean shift algorithm-based color segmentation procedure. Then, object probabilistic maps were generated with pre-trained thresholds using Gaussian mixture models and weighted blob-size and location feature vectors.
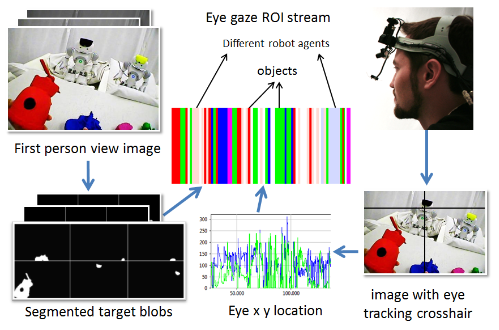
After identifying the Region-Of-Interest (ROI) that the participant was gazing at, this information was sent to the robotic agents. Based on where the participants were looking at in real time and the visual information in the robots' view, the robotic agents would start looking at the participant to create mutual gaze or follow the participant's gaze to create joint attention momements under different cooperative condition. Joint attention or shared attention referes to the moments when two or more participants look at the same target object or area of focus at the same time. The complete diagram of signal transfer between the robotic agents and the participant was shown below.
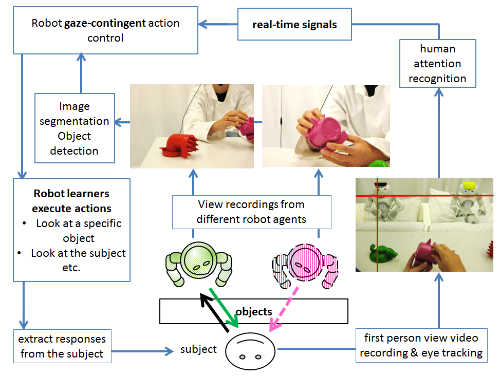
With this platform, the robots’ behaviors can be triggered by the participant’s attentional shifts in real time (and other behavioral cues as well). By taking all the lags in this real-time control system into account, several rounds of empirical tests revealed that the robot’s response time was comparable to human's response time in face-to-face interaction with gaze following lag between 300ms to 800ms (657ms on average). Please see the videos below from two of our experiments.